Dataset
The data set in our project contains many attributes: Ref(Radar reflectivity in km), RefComposite(Maximum reflectivity), RhoHV(Correlation coefficient), Zdr(Differential reflectivity), Kdp(Specific differential phase) and so on. But the most important attribute is Ref, which is highly related to the rainfall. Our raw data set contains more than 1000000 different ids, and each id represents a radar’s observation in about 6 time slots, so the total size of our data set is about 6000000. In each id, we have an expected rainfall value, which is collected by the rain gauges and it represents the real rainfall in those areas.
Preprocess
Our data set is too big and it contains many blank due to some reason in measurement, so we have to do data preprocessing for our training. Our strategy is to calculate the mean value for each attribute to generate one observation for each id to make our data more clear and succinct. Also, we will discard some ids with too many blanks or a too big expected rainfall(over 70).
In our training and validation, we use ten fold cross validation to gain the accuracy. We firstly separate our data into ten equal parts, and then use 9 of them for training and the remain one for validation. We use MAE(Mean Absolute Difference) to calculate the difference between our output and the expected value in rainfall to estimate our accuracy.
Random Forest

Ref

Ref + Zdr + Kdp

0.5 dBZ + 0.5 RZK

0.7 dBZ + 0.3 RZK
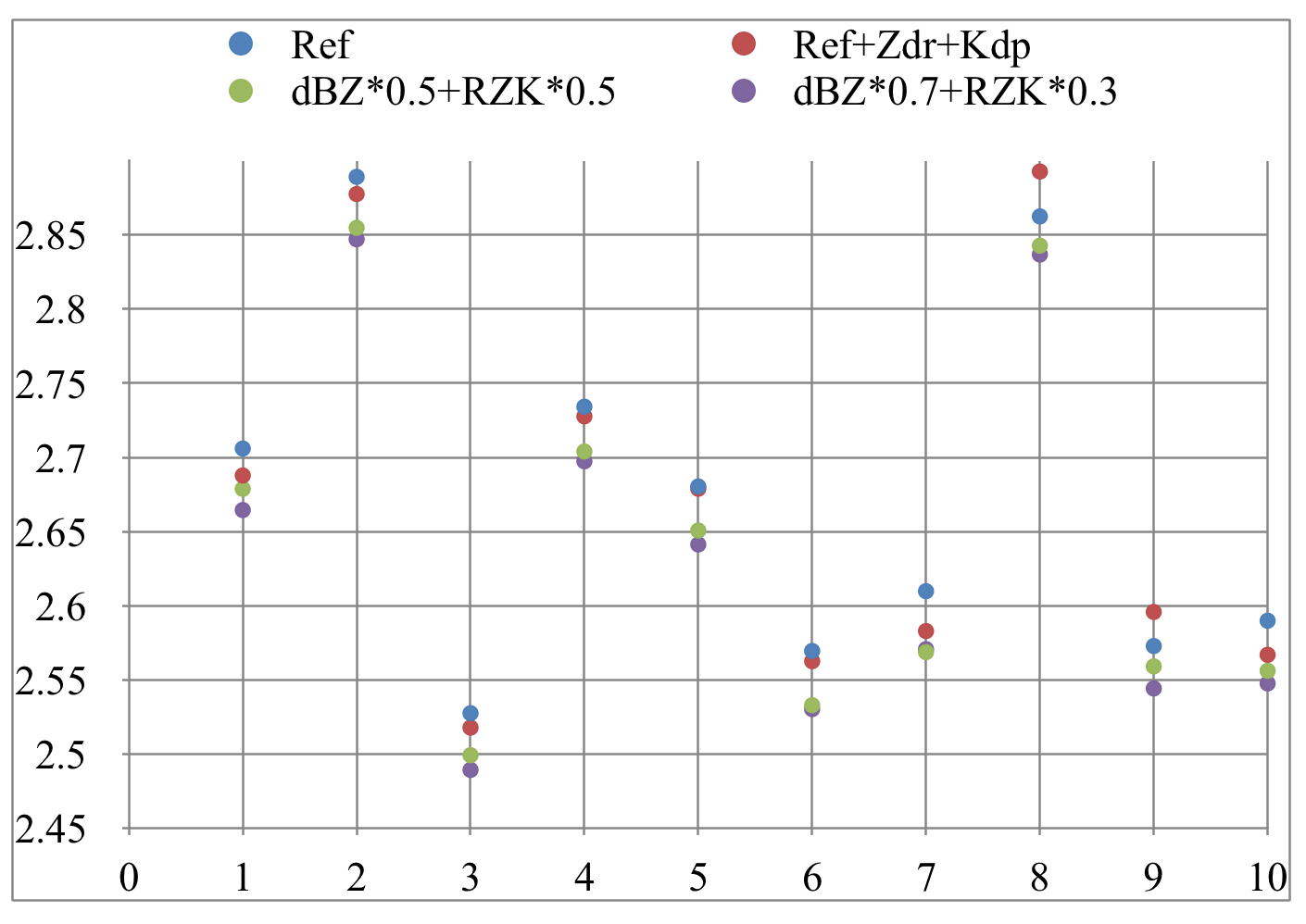
comparison of different implementations of Random Forest
XGBoost

XGBoost

0.7 XGBoost + 0.3 dBZ
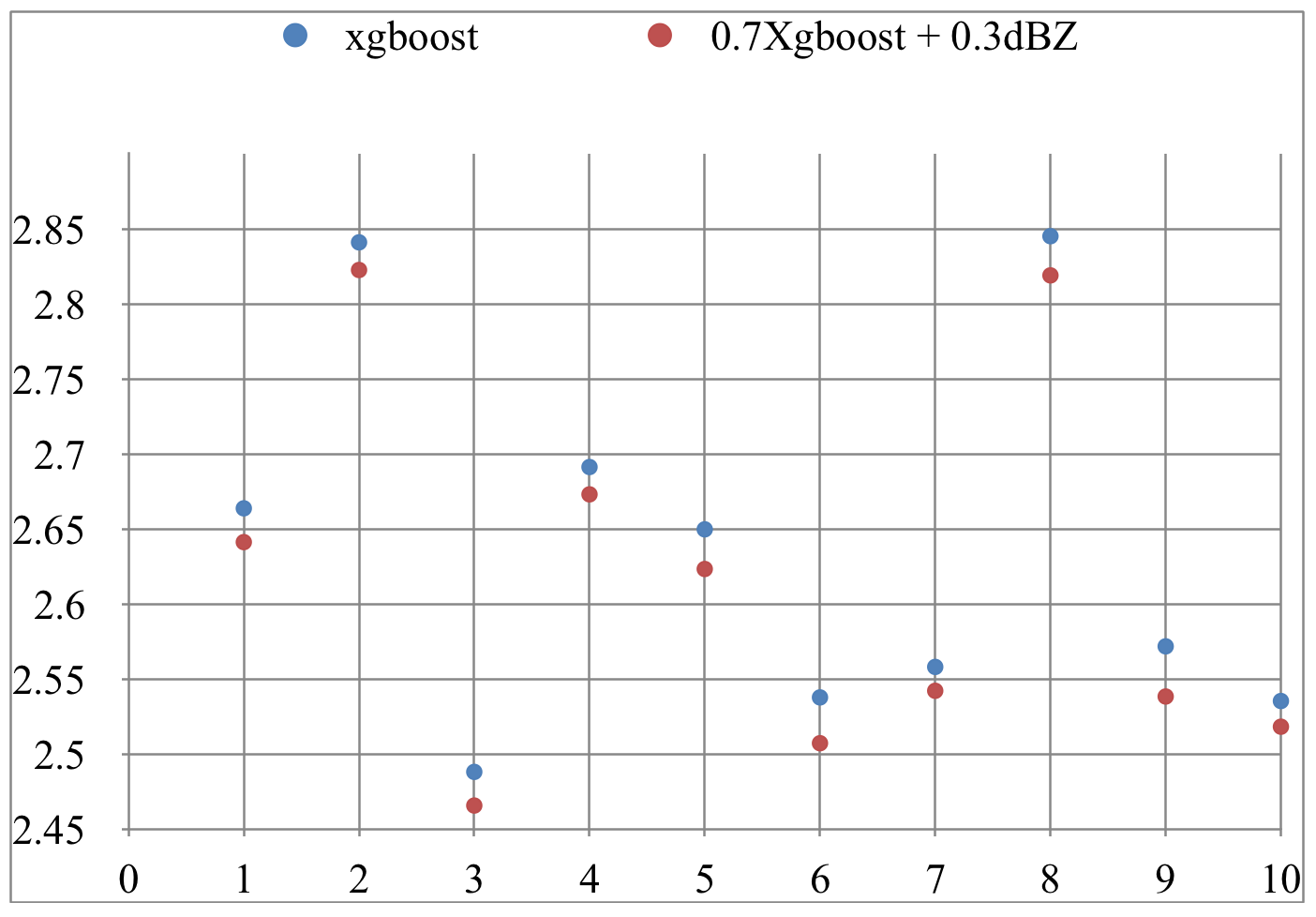
compariaon of different implementations of XGBoost
IBk

IBk