QPE
Our project is a radar-based Quantitative Precipitation Estimates (QPE) problem, estimating the hourly rainfall by using data collected from the radar. Our project can help to estimate the rainfall via radar observations, which is cheap and feasible.

Solution
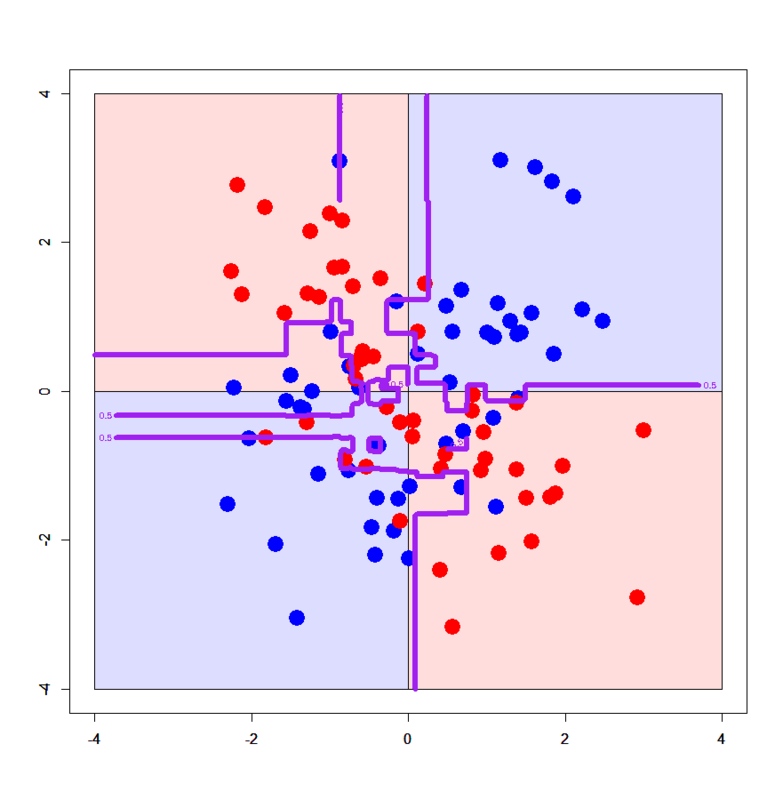
We provide some solutions to estimate rainfall based on the radar measurements. We analyze the results of three different methods (Random Forest, XGBoost and IBk) and compare their performances.

Sample Data
If you are interested in the data we used for estimation, check it by yourself! You can read the explanation of the attributes in the data from our report if you have problems.